Instructions for Using the Search Engine
This guide describes how to use the resources available in the Corpus of Historical Polish Dramatic Texts (1772–1939) [KorTeDa] via the search engine at www.korteda.clarin-pl.eu. This document is an extended and modified version of the corpus functionality description included in the article by Mitrenga B., Pastuch M., Wąsińska K. (in print).
KorTeDa (version released in May 2025) contains over 800,000 segments and includes 50 dramatic texts written between 1772–1939. These are originally Polish plays with social themes, selected based on their linguistic characteristics. The criteria for selecting texts for the corpus are detailed under the “About the Corpus” section.
Search Options
The search engine offers two ways of querying the corpus texts: 1) by base form (i.e. lemma), 2) by orthographic form (the exact realization of the word in the text).
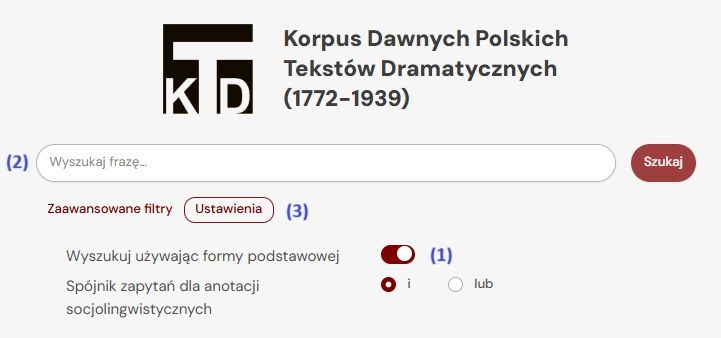
The default is “Search by base form” (1), which means that entering a base form (e.g. noun in nominative singular, adjective in masculine nominative singular, verb in infinitive) in the “Search phrase…” field (2) will return results for all inflected forms of the word. For invariable words, entering the form in the search box returns all occurrences. To search for a specific grammatical (orthographic) form, go to the “Settings” panel (3) and disable search by base form (1). Once disabled, letter case matters — for example, to find the form “domu”, you must query both “domu” and “Domu”, then sum the results.
All texts in KorTeDa were corrected after OCR conversion. However, some typos (e.g. character omissions or incorrect insertions) may remain. Some words not present in the original texts may appear due to OCR errors, especially if they match valid Polish dictionary entries (e.g., “Gnido Reni” instead of “Guido Reni”). Original errors in source material were not corrected during the review process.
Incorrect part-of-speech tagging may lead to wrong grammatical annotations, e.g. “Co dziś śpiewać mamy” tagged as noun:sg:gen:f (from "mama") instead of from "mieć"; “Jesteś pan niegodziwiec, potwór” tagged as noun:pl:gen:f (from "potwora") instead of "potwór". Such cases are rare but possible.
Search Results View
Search results appear in a column with the character's name (4) and their spoken line in the drama (5). A plus icon expands the context to surrounding lines from other characters (6), and a minus icon collapses the expanded view (7).
The result containing the search phrase can be copied (8). Hovering over the icon (9) shows a list of characters in the scene; clicking it opens a card with all characters in the drama. Drama metadata (e.g. title, author, year) is under icon (10). All such information is also available in the “Texts in the Corpus” section. A link to the full text of the work is provided via icon (11).
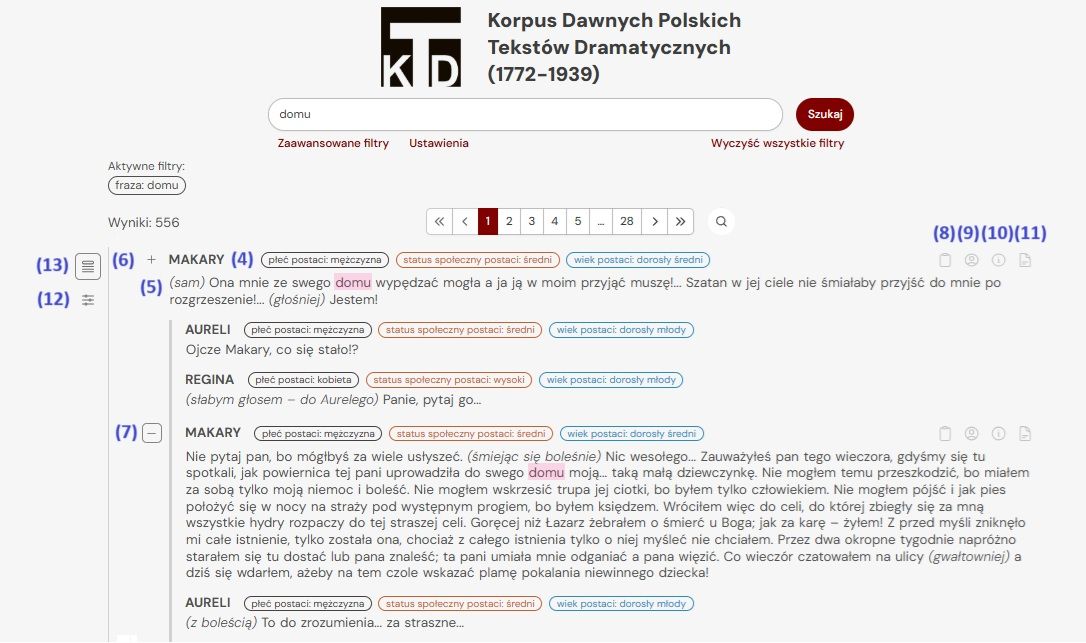
The corpus automatically searches dialogue segments annotated morphosyntactically and sociolinguistically. Preview settings (12) allow additional options: - search collective utterances (not sociolinguistically marked); - search stage directions (not sociolinguistically marked); - show morphosyntactic information about words (tags follow the NKJP format: https://nkjp.pl/poliqarp/help/ense2.html); - show sociolinguistic data about the speaker (age, gender, and social status); - set the number of utterances before and after the hit to show (1–5). Return to the results window using icon (13).
Search Filters
The “Advanced Filters” tab (14) allows restricting the search space based on two criteria: text metadata and sociolinguistic parameters of speakers. Specific filter values can be selected within each section.

Filtering by Metadata
All texts are tagged with metadata such as author, title, place of publication, text type, etc. Most of these serve as search filters and can be used to limit the search space. In the “Advanced Filters” tab (14), under “Metadata” (15), you’ll find: author, author gender, title, time period, text type, and publication place.
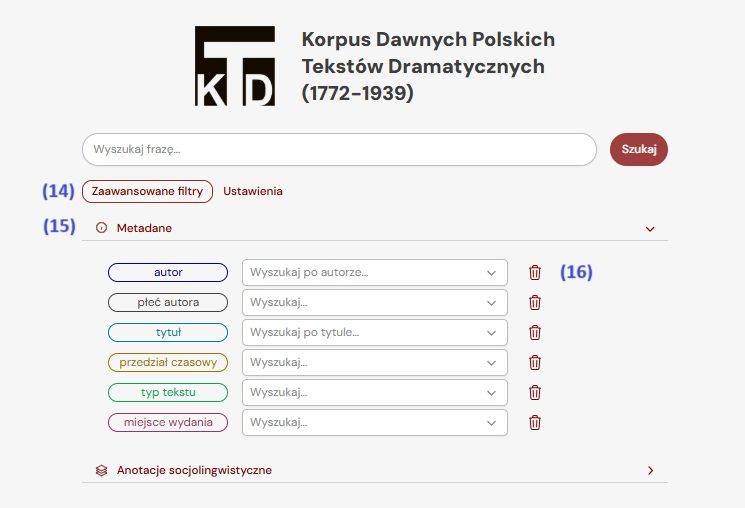
Each metadata field applies specific filtering: - author: all authors are known and listed as per the title page. The "Search by author…" field provides an alphabetical list. - author gender: values are F – female and M – male. Useful for filtering without selecting specific names. - title: All works in KorTeDa have a title, modernized for clarity (e.g. “Seven Times One” instead of “Siedm razy jeden”), standardized based on the publication *Dramat polski 1765–2005* (Stafiej et al., 2014). - time period: Six periods are defined: 1772–1800, 1801–1825, 1826–1850, 1851–1875, 1876–1900, 1901–1939. This allows for comparative or diachronic research. - text type: While all texts are dramas, they differ in genre (e.g., comic opera, farce, scenic sketch), based on subtitles or, if missing, the classification from *Dramat polski*. - place of publication: Sourced from title pages. For dual locations (e.g., Lviv–Warsaw), filtering can use either. Trash icons next to each metadata field (16) remove applied restrictions. Aside from filtering metadata, identifying metadata such as year of creation, year of publication, abbreviation, subtitle, and source are listed in the “Texts in the Corpus” section.
Filtering by Sociolinguistic Parameters
All characters' utterances are annotated with gender, age, and social status. These values are discussed in Pastuch M., Mitrenga B., Wąsińska K. 2024. Filters can be combined — selecting values across or within categories (17). For example, you can search only female utterances or only those from middle/low social status individuals, or combine: middle-aged women of low status. When selecting two or more values, specify the query operator in settings (3): and — to intersect values, or — to union values. For example, with “adult middle-aged” and “high status”, the and operator yields utterances by middle-aged adults with high status, while or returns both middle-aged adults (any status) and high-status individuals (any age). Sociolinguistic filters can be combined with metadata filters (15). All applied filters are shown below (18). Reset them using the reset button (19).
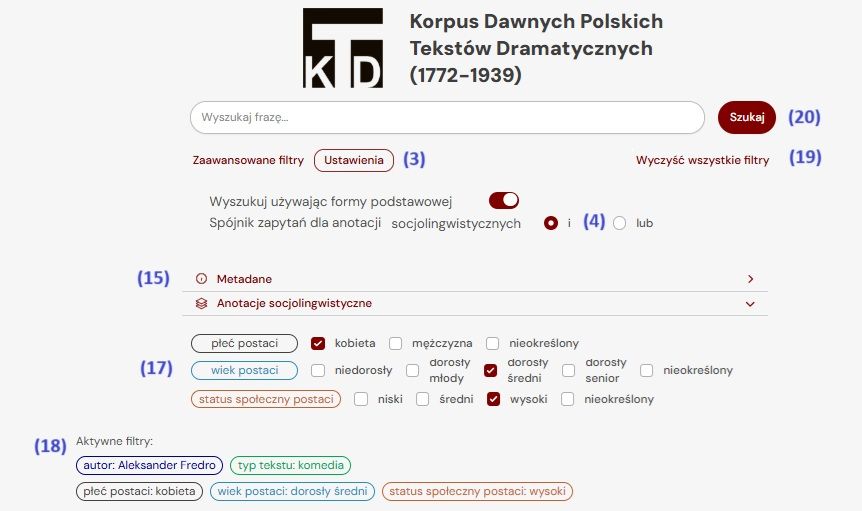
Clicking the “Search” button (20) displays the results list. Sociolinguistic values appear next to the character's name (21), unless this is disabled in preview settings (12). Group scenes and stage directions are not sociolinguistically annotated.
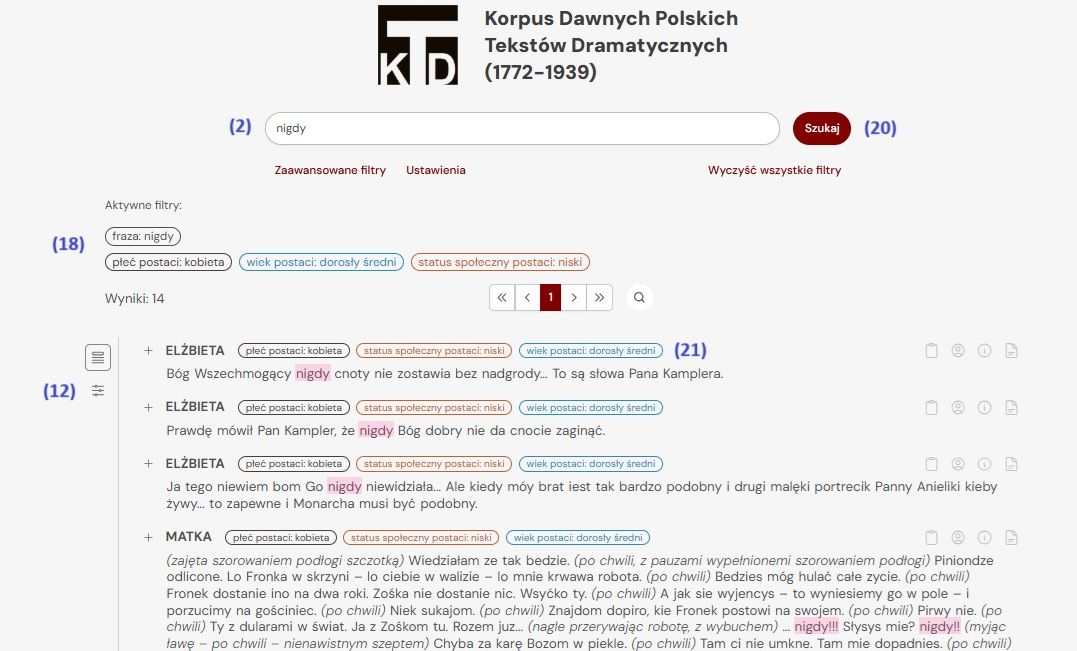
The search engine thus allows locating a specific word entered in the “Search phrase…” field (2) within a filtered subset of texts (18). It also supports browsing utterances by characters with selected traits even without entering a search phrase. In that case, leave the search field empty and click “Search” (20).
Additional Corpus Functionalities
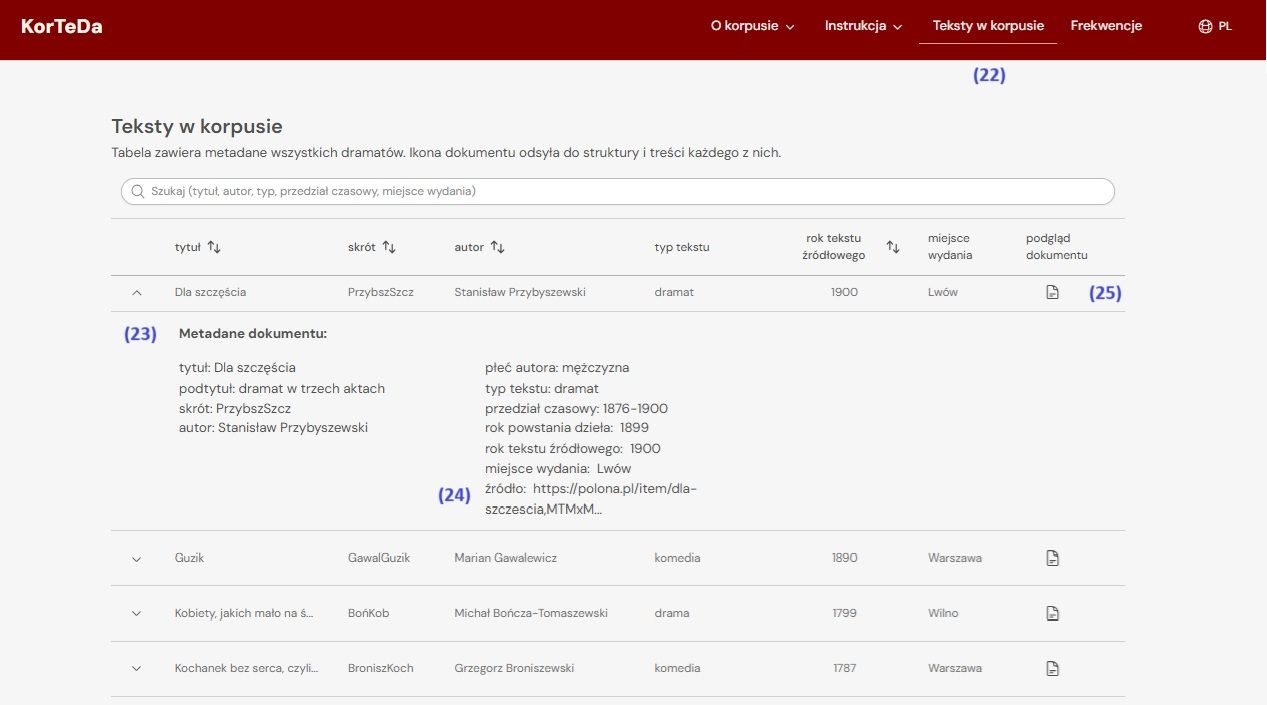
In addition to advanced search, KorTeDa provides access to the full texts. The “Texts in the Corpus” tab (22) lists all texts, their metadata (23), a link to the original source (24), and a structured view prepared specifically for KorTeDa (25).
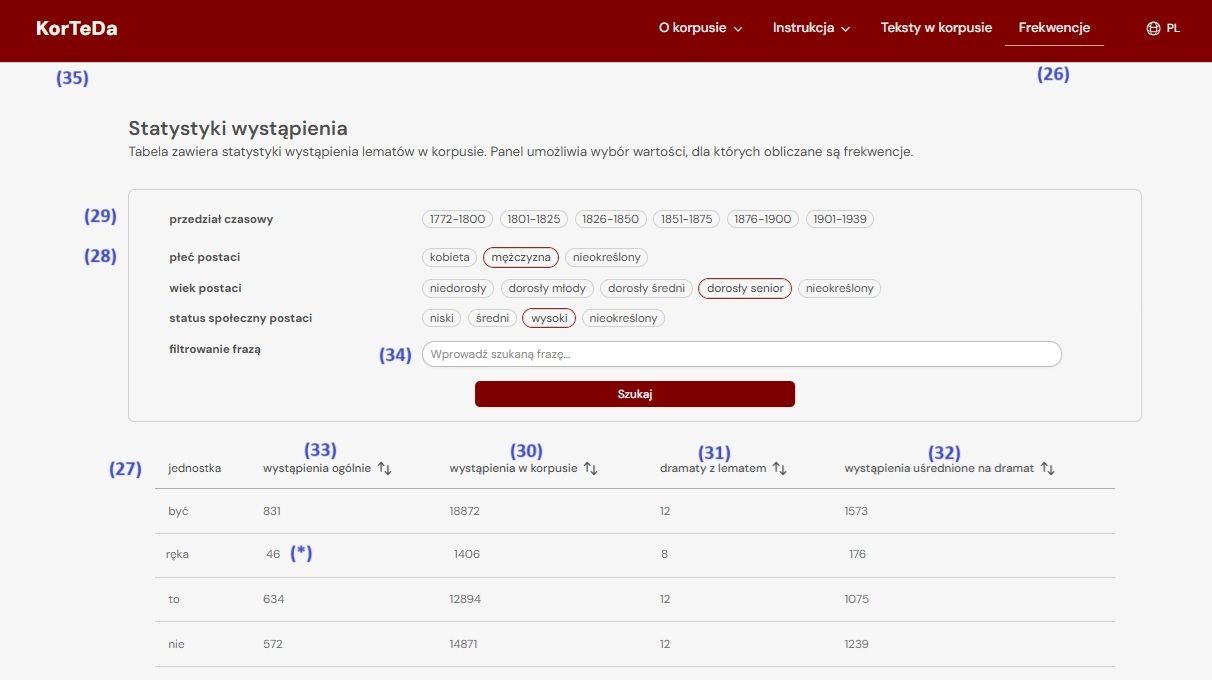
The “Frequencies” tab (26) displays statistics on specific items (27) and their occurrence across the corpus, filtered by sociolinguistic categories (28). You can also filter by time period (29). It shows not just total occurrences (30), but also the number of dramas containing the term (31), and calculates average frequency per drama (32). After selecting a sociolinguistic profile, the tool shows how often a word appears, e.g., the word “ręka” (hand) appears 46 times in utterances by high-status, senior adult men, but 1397 times in total across 8 plays. The “Frequencies” function also includes a general word ranking and allows targeted queries. Enter a word in field (34) and click “Search” to display stats. If no frequency filters are applied, the corpus frequency (30) equals the overall count (33).
Return to the search homepage by clicking the corpus acronym in the top-left corner (35).
Pastuch M., Mitrenga B., Wąsińska K., 2024, Sociolinguistic annotation in the Corpus of Historical Polish Dramatic Texts (1772–1939), “LingVaria”, no. 1( 37), pp. 151–170. https://doi.org/10.12797/LV.19.2024.37.10
Stafiej, A., Michalik, J., & Hałabuda, S., 2014, Polish Drama 1765–2005. Performances, Prints, Archives. Vol. 1–3. Wydawnictwo Księgarnia Akademicka.